

The grep command in Linux is used to search for a specific text string in any file. This is a really powerful tool which you can use in several ways by searching for new lines, lines having no uppercase letters and many more ways. The grep command, however, does not work with PDF files.
That’s where pdfgrep command comes in. It is essentially ‘grep’ but for PDF files. In this tutorial, I will guide you through the usage and installation process of this command.
Installing pdfgrep
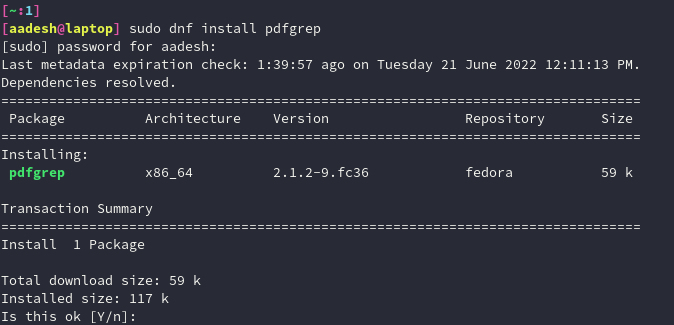
This command, although it does not ship with all the Linux distributions, is available in the official repositories of all the package managers. To install it, you can use the following command, depending upon your Linux distribution :
# On Debian and Ubuntu-based distributions
sudo apt update && sudo apt install pdfgrep
# On Fedora Workstation
sudo dnf install pdfgrep
# On Arch Linux
sudo pacman -S pdfgrep
Usage of pdfgrep
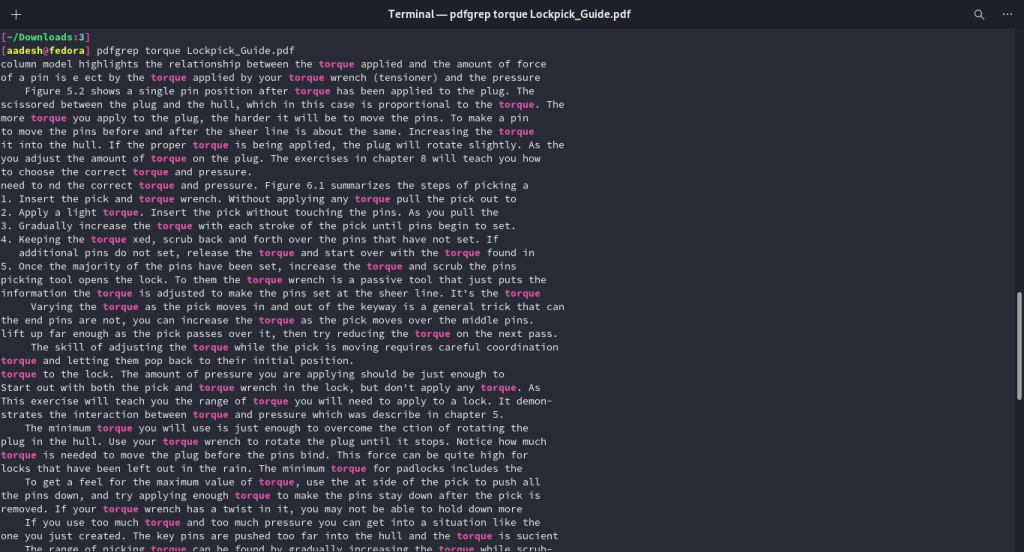
If you have used the grep command before, then this utility will feel familiar to you. The basic usage of this command is as follows:
pdfgrep Search_String FILENAME.pdf
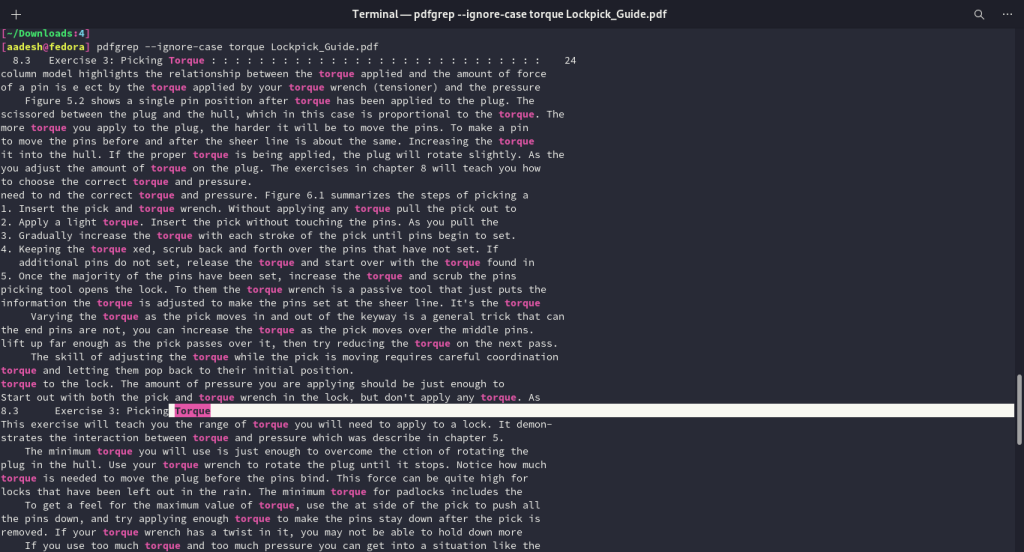
Perhaps you would want to perform a case-insensitive search because the search string can be capitalized in the document. You can use the --ignore-case flag with the command.
pdfgrep --ignore-case Search_Strng FILENAME.pdf
You can also get the total number of search results directly in the terminal by using the -c option along with the full command:
pdfgrep --ignore-case Search_Strng FILENAME.pdf --count
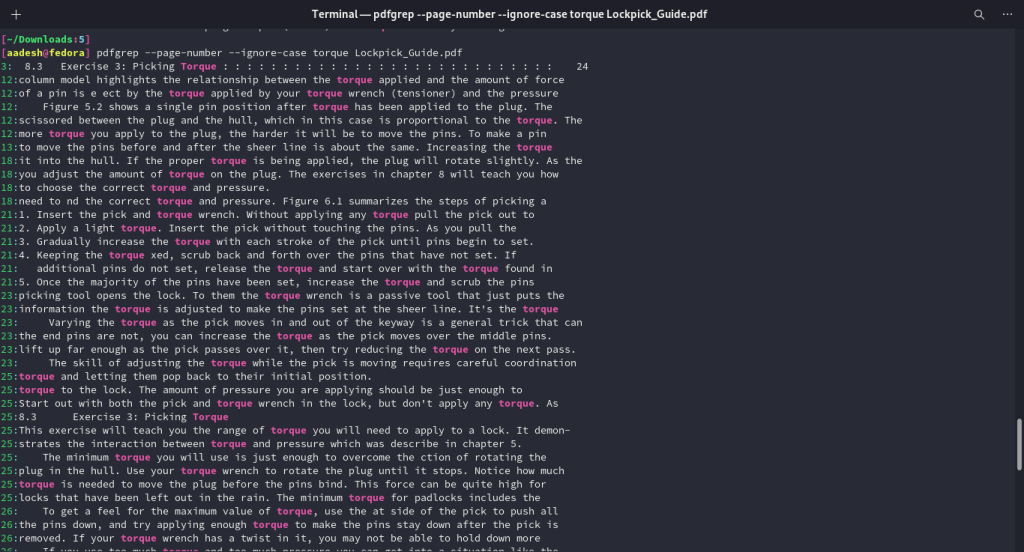
Since PDF documents have page numbers, you can also get the page number on which your search string is present. You can use the --page-number option along with the whole command:
pdfgrep --page-number --ignore-case Search_String FILENAME.pdf
There is also a way through which you can search in a password-protected PDF file. Keep the rest of the command same and then just add --password option to it along with the password of the locked document.
pdfgrep --password YOUR-PASSWORD Search_String FILENAME.pdf
Summary
What makes pdfgrep great, in my opinion, is its similarity with the grep command, therefore making it easier for the users, by not making them remember new command and options for basically the same functionality.
References
Arch Linux Manual page on pdfgrep