

In this article we discuss how to shallow clone on Git. We’ll go over the differences between the default git clone command and the shallow clone and then learn how to create a shallow clone on git.
What is the problem with the default git clone?
The default clone command in git copies all the information about all the reversions made to a file in all branches. Over time this commit-tree/graph becomes deeper and deeper as more branches are created and commits are made to the repository.
This causes some serious cloning issues for large repositories with huge commit history.
Some of the commit histories including trees and blobs are redundant in some cases, e.g: If you are working on a project that is years old, storing the history of the first commit will make little sense from a storage point of view.
So in cases where you don’t require all of the commit histories of all of the files, the default git clone doesn’t really serve the purpose.
What is shallow clone?
The shallow clone lets you truncate the commits history to the latest commits i.e. instead of all the commit history, only the last few commits are downloaded. The leaves of the commit tree are pruned out, making the cloned commit-graph shallower. Here is beautiful graphical explanation from a GitHub Blog by Derrick Stolee.
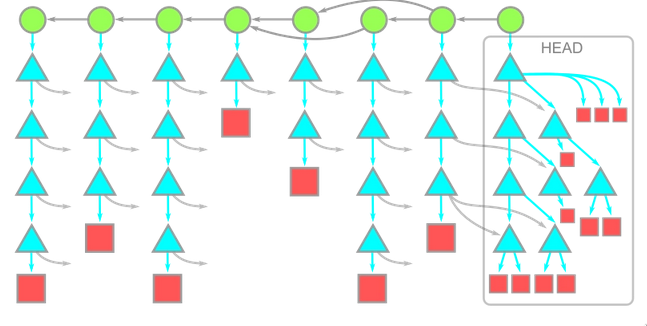
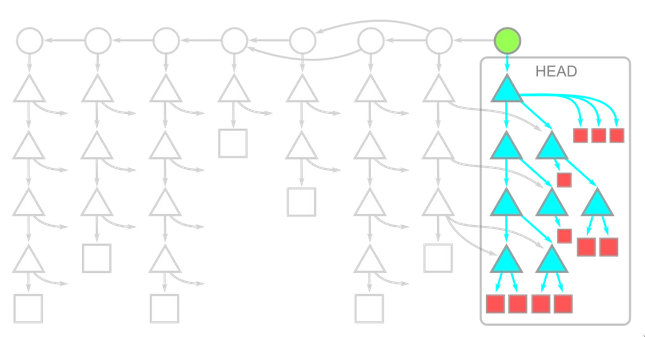
“In these diagram, time moves from left to right. The arrows between a commit and its parents therefore go from right to left. Each commit has a single root tree. The root tree at the HEAD commit is fully expanded underneath, while the rest of the trees have arrows pointing towards these objects.”
Here comparing these two diagrams we see that recent commit head and it’s attached trees are detached from it’s parent(These commits detached from it’s parent are called shallow commits and are represented by the single green node in Fig 2).
How to shallow clone?
We can mention the depth of the repository by using the depth flag followed by a natural number representing the depth of the git commit tree.
git clone --depth <depth> <upstream-repository-link>
Here is an example usage to clone with only the latest commit node:
git clone --depth=1 https://github.com/Dsantra92/Google-Form-Automation
Problems and alternate options
Shallow clone is very efficient for cloning only the files with no revision history. This can be beneficial for many continuous integration(CI) processes where we delete the repository at the end of the build. It can also be very useful for making quick commits into the repository. But detaching the head from the commit history has it’s own set of consequences:
- Git commands such as git merge-base and git log does not show results as expected in full clone.
- Commands like git-blame does not work.
- Git fetch can be a little computationally expensive than git-fetch in a full clone because the the server mus provide every tree and blob which are “relatively” new to these commits.
So make sure to understand your use case and use the depth flag wisely.
References:




