
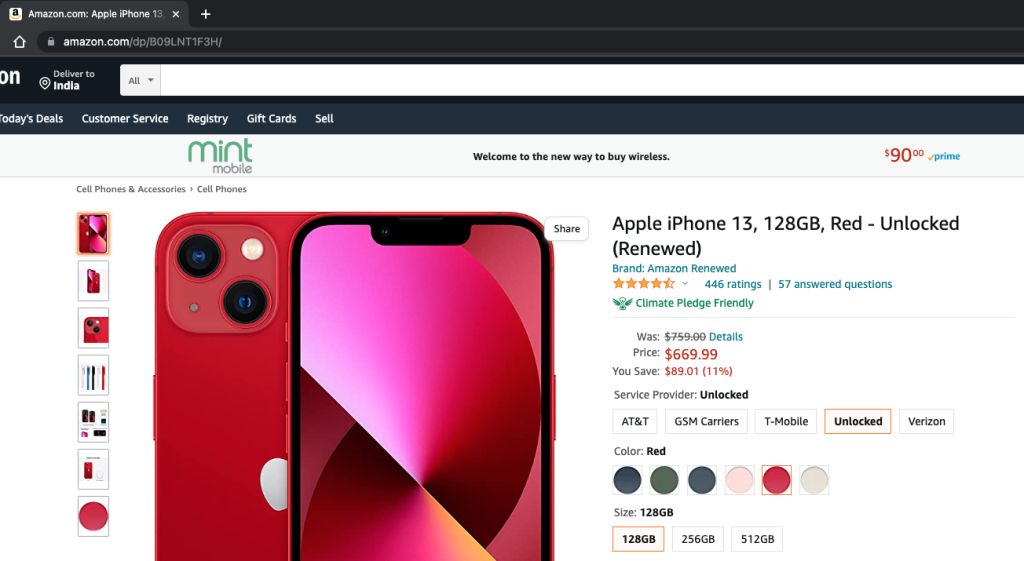
Did you notice that discount on the iPhone 13 on Amazon? Well, Apple doesn’t provide a lot of discounts and I wanted to track their pricing changes for a few days. It’s not possible to do it manually, so I thought to write a web scraping program and then run it on my Linux machine as a cronjob to track the pricing changes.
Amazon Scraper Python Program
Thankfully, I got the Python program to scrape the Amazon product page from this CodeForGeek tutorial. But, my requirement was a little more. So, I extended the code by adding functionality to save the data into a CSV file.
Here is my complete Python code to scrape the amazon product page and then save it into a CSV file.
from bs4 import BeautifulSoup
import requests
URL = 'https://www.amazon.com/dp/B09LNT1F3H/'
HEADERS = ({
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 44.0.2403.157 Safari / 537.36',
'Accept-Language': 'en-US, en;q=0.5'})
webpage = requests.get(URL, headers=HEADERS)
soup = BeautifulSoup(webpage.content, "lxml")
product_name = ''
product_price = ''
try:
product_title = soup.find("span",
attrs={"id": 'productTitle'})
product_name = product_title.string.strip().replace(',', '')
except AttributeError:
product_name = "NA"
try:
product_price = soup.find("span", attrs={'class': 'a-offscreen'}).string.strip().replace(',', '')
except AttributeError:
product_price = "NA"
print("product Title = ", product_name)
print("product Price = ", product_price)
# writing data to a CSV file
import datetime
import csv
time_now = datetime.datetime.now().strftime('%d %b, %Y %H:%M:%S')
with open("data.csv", mode="a") as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow([time_now, product_name, product_price])
Setting up Cronjob
I saved the code into the amazon_scraper.py file. For the sake of testing, I set up the crontab to run every 5 minutes using the below configuration.
*/5 * * * * cd /root/amazon_scraper && /usr/bin/python3.8 /root/amazon_scraper/amazon_scraper.py >> /root/amazon_scraper/scraper.log 2>&1
After some time, I checked the data.csv file and it had the following entries.
"10 Sep, 2022 19:50:43",Apple iPhone 13 128GB Red - Unlocked (Renewed),$759.00
"10 Sep, 2022 20:00:04",Apple iPhone 13 128GB Red - Unlocked (Renewed),$759.00
"10 Sep, 2022 20:05:03",Apple iPhone 13 128GB Red - Unlocked (Renewed),$759.00
"10 Sep, 2022 20:10:05",Apple iPhone 13 128GB Red - Unlocked (Renewed),$759.00
"10 Sep, 2022 20:15:04",Apple iPhone 13 128GB Red - Unlocked (Renewed),$759.00
You can see that there are a few print() statements. This console output is directed to the scraper.log file.
root@localhost:~/amazon_scraper# cat scraper.log
product Title = Apple iPhone 13 128GB Red - Unlocked (Renewed)
product Price = $759.00
product Title = Apple iPhone 13 128GB Red - Unlocked (Renewed)
product Price = $759.00
product Title = Apple iPhone 13 128GB Red - Unlocked (Renewed)
product Price = $759.00
product Title = Apple iPhone 13 128GB Red - Unlocked (Renewed)
product Price = $759.00
If there are any errors, they will also go into this log file. So you can check this file to debug for any issues.
Bulk Scraping and Request Blocking
My program is just for learning purposes. If you will try to run it for a lot of products, there is a high chance that Amazon will block your IP. If you have some enterprise-like requirements, it’s best to go with third-party tools such as this BrightData Amazon Scraper.
Conclusion
Web scraping with Python is very easy and when it’s set up to run as a cronjob, you can track pricing changes of any product. It’s fun at the personal level but if you require to process bulk data, the best option is to go with some enterprise tools.